

AI Training Dataset Market Size, Regional Outlook
AI Training Dataset 2024
The rapid advancement of artificial intelligence (AI) technology has fundamentally transformed various sectors, driving innovations that were previously unimaginable. At the heart of this transformation lies the AI training dataset, a critical component that enables machine learning models to learn, adapt, and improve over time. Training datasets comprise vast amounts of data used to teach AI systems how to recognize patterns, make predictions, and perform tasks effectively. As the demand for AI applications continues to grow, the AI Training Dataset Market Share has become increasingly significant, reflecting the essential role that high-quality data plays in the development of robust AI models.
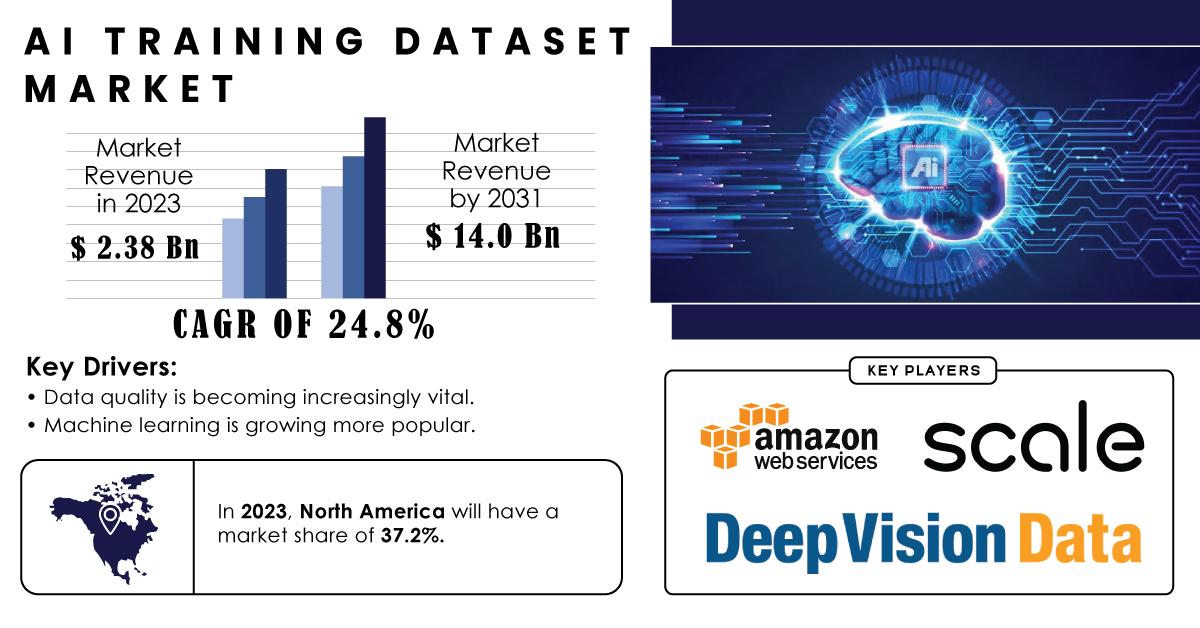
The AI Training Dataset Market was valued at USD 2.38 billion in 2023 and is expected to increase to USD 14.0 billion by 2031, expanding at a CAGR of 24.8% between 2024 and 2031. This remarkable growth is fueled by the increasing adoption of AI across various industries, including healthcare, finance, automotive, and retail. Organizations recognize that the success of AI initiatives hinges on the quality and diversity of the datasets used for training, leading to an increased focus on sourcing, curating, and managing training datasets effectively.
The Importance of AI Training Datasets
AI training datasets serve as the foundation upon which machine learning models are built. These datasets consist of labeled examples that allow algorithms to understand the relationships between input data and the desired outputs. For instance, in image recognition tasks, a training dataset might include thousands of labeled images, enabling the AI model to learn how to identify and categorize different objects within those images.
The quality of the training dataset directly influences the performance of the AI model. High-quality datasets are characterized by their accuracy, diversity, and relevance to the specific task at hand. If the dataset is biased or contains errors, the resulting AI model may also exhibit biased behavior or make incorrect predictions. Thus, ensuring data quality is paramount for organizations seeking to deploy effective AI solutions.
Moreover, the growing complexity of AI applications necessitates the use of larger and more sophisticated training datasets. Traditional datasets may not suffice for modern machine learning models, which require extensive amounts of data to learn effectively. As a result, organizations are increasingly investing in the creation and acquisition of diverse datasets that cover a wide range of scenarios and conditions.
Types of AI Training Datasets
AI training datasets can be categorized based on various factors, including the type of data they contain and the specific use cases they address. Common types of datasets include image datasets, text datasets, audio datasets, and video datasets, each tailored for different AI applications.
Image datasets are particularly crucial for computer vision tasks, such as object detection, facial recognition, and image segmentation. These datasets often include millions of labeled images that enable models to learn how to interpret visual information effectively. Notable examples of image datasets include ImageNet and COCO, which have been instrumental in advancing the field of computer vision.
Text datasets are essential for natural language processing (NLP) applications, enabling AI models to understand and generate human language. These datasets may contain a wide array of text sources, including books, articles, and social media posts. Popular text datasets, such as the Common Crawl and the Stanford Question Answering Dataset (SQuAD), are widely used for training language models.
Audio datasets are critical for speech recognition and audio analysis tasks. They provide the necessary training data for models to learn how to understand and transcribe spoken language, as well as analyze various audio signals. Datasets like LibriSpeech and VoxCeleb are commonly used in the development of speech recognition systems.
Video datasets combine multiple data types, incorporating both visual and auditory information. These datasets are essential for tasks such as video classification, object tracking, and action recognition. Examples include the UCF101 dataset and the Kinetics dataset, which have been pivotal in advancing research in video understanding.
Challenges in Creating AI Training Datasets
Despite the crucial role that AI training datasets play in the development of AI models, several challenges can hinder their creation and management. One of the primary challenges is data collection. Sourcing high-quality data can be a time-consuming and resource-intensive process, especially for specialized applications. Organizations must ensure that their datasets are comprehensive, diverse, and representative of the real-world scenarios the AI model will encounter.
Data privacy and security are also significant concerns in the creation of training datasets. With increasing regulations governing data protection, organizations must navigate legal complexities when collecting and using data, especially when it comes to personal or sensitive information. Ensuring compliance with regulations such as the General Data Protection Regulation (GDPR) is crucial to avoid legal repercussions and maintain customer trust.
Additionally, the potential for bias in training datasets poses a substantial risk. If datasets are not representative of the broader population or contain biased information, AI models may learn and perpetuate these biases, leading to unfair or discriminatory outcomes. Organizations must actively work to identify and mitigate biases within their datasets, employing techniques such as data augmentation and bias detection algorithms to create more equitable AI systems.
The Role of Data Annotation
Data annotation is a critical step in the development of high-quality AI training datasets. This process involves labeling or tagging data to provide context and meaning, allowing machine learning algorithms to learn from the information effectively. Accurate data annotation is vital for training models, as it directly impacts their ability to make predictions and perform tasks accurately.
Various methods of data annotation exist, including manual annotation, where human annotators label data, and automated annotation, which employs algorithms to generate labels. While manual annotation can yield high accuracy, it is often time-consuming and costly. Automated methods, on the other hand, can significantly speed up the annotation process, though they may require additional oversight to ensure accuracy.
In recent years, advancements in AI technologies have led to the emergence of semi-automated and collaborative annotation platforms, which combine human expertise with automated tools to improve efficiency and accuracy. These platforms enable organizations to streamline the annotation process, reduce costs, and enhance the quality of their training datasets.
Future Trends in AI Training Datasets
As the AI landscape continues to evolve, several trends are likely to shape the future of AI training datasets. One notable trend is the increasing reliance on synthetic data generation. Organizations are beginning to explore the use of synthetic datasets—data generated by algorithms rather than collected from the real world—to supplement their training datasets. This approach can help overcome challenges related to data scarcity, privacy concerns, and bias, as synthetic data can be tailored to specific requirements.
Another trend is the growing emphasis on open data initiatives. Open data allows organizations to share their datasets with the broader research community, fostering collaboration and innovation. By providing access to high-quality datasets, organizations can accelerate AI research and development, driving advancements across various fields.
Additionally, the integration of federated learning is expected to gain traction. This approach enables AI models to be trained on decentralized data sources without transferring the data itself to a central server. Federated learning enhances data privacy and security, making it an appealing option for organizations that handle sensitive information.
Conclusion
The AI training dataset market is on a remarkable growth trajectory, fueled by the increasing demand for AI technologies across multiple industries. As organizations recognize the critical role of high-quality datasets in developing effective AI models, they are investing more resources in sourcing, curating, and managing training datasets. Despite the challenges associated with data collection, privacy, and bias, innovations in data annotation, synthetic data generation, and open data initiatives are paving the way for more robust and equitable AI systems.
As we look to the future, the role of AI training datasets will only become more prominent, underscoring their importance as the foundation of artificial intelligence. With continued advancements in data technologies and methodologies, organizations can harness the power of AI to unlock new opportunities and drive transformative change across sectors.
Contact Us:
Akash Anand – Head of Business Development & Strategy
info@snsinsider.com
Phone: +1-415-230-0044 (US) | +91-7798602273 (IND)
About Us
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Read Our Other Reports: