

AI Training Dataset Market Share, Research Forecast
AI Training Dataset 2024
As artificial intelligence (AI) continues to transform industries, the importance of high-quality training datasets has become paramount. AI systems rely on large volumes of data to learn patterns, make decisions, and deliver insights with increasing accuracy. An AI training dataset is the structured and labeled data used to train machine learning algorithms, enabling them to recognize patterns and improve over time. From medical imaging in healthcare to predictive analytics in finance, training datasets are foundational to the performance and reliability of AI applications. The demand for these datasets has spurred significant AI Training Dataset Market Growth as organizations seek refined, high-quality data to optimize their AI models.
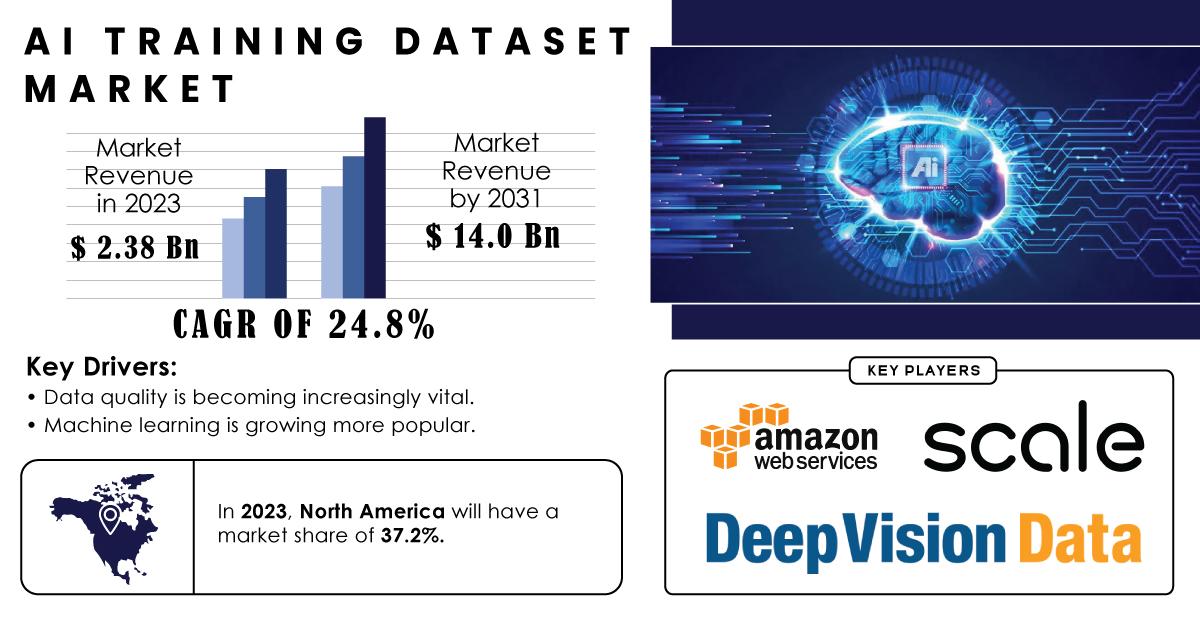
AI models learn through supervised and unsupervised training, where they either require labeled data (supervised) or self-identify patterns within unstructured datasets (unsupervised). Without a comprehensive training dataset, AI systems would lack the contextual knowledge to process data meaningfully or accurately make decisions, which could lead to biased or inaccurate outcomes. The AI Training Dataset Market was valued at USD 2.38 billion in 2023 and is expected to increase to USD 14.0 billion by 2031, expanding at a CAGR of 24.8% between 2024 and 2031.
Importance of High-Quality Datasets
The quality of an AI model is intrinsically linked to the quality of its training data. A dataset that is rich in diversity, accuracy, and representation enables the AI to develop nuanced understanding, improving the model's robustness and reducing bias. In applications like self-driving vehicles, where safety is paramount, high-quality training datasets allow the model to accurately interpret road conditions, signs, and potential hazards. Similarly, in healthcare, properly labeled medical images help AI in diagnosing diseases with precision. High-quality datasets empower AI to deliver reliable, fair, and accurate results across sectors.
The diversity within a dataset is also crucial to reducing model bias, especially in applications involving social or human-centric data, such as natural language processing (NLP) and facial recognition. If a dataset is too homogeneous, AI systems might fail to accurately interpret or recognize patterns outside of that data scope, leading to biases or misinterpretations in real-world applications. Creating datasets that reflect a wide range of demographics, languages, and scenarios helps AI systems become more inclusive and adaptable.
Types of AI Training Datasets
Training datasets can vary greatly depending on the type of AI application being developed. For instance, image and video datasets are critical for computer vision, helping AI models learn to recognize objects, people, and complex visual scenarios. In NLP, text datasets allow AI to understand language, context, and sentiment, forming the basis for applications like chatbots, translation services, and sentiment analysis. Other common types of datasets include audio data for speech recognition and structured data for financial or transactional analysis.
These datasets may be publicly sourced, generated through synthetic data creation, or curated from proprietary sources. Public datasets, like those available through research institutions, are commonly used for academic AI development. In contrast, private companies may rely on proprietary datasets to gain competitive advantages, particularly when dealing with sensitive or high-value information. Synthetic data, which is artificially generated, is becoming increasingly popular as it allows for dataset expansion without additional data collection, providing cost-effective and scalable solutions for training AI models.
Challenges in Building Effective AI Training Datasets
Building a reliable AI training dataset is not without its challenges. Data quality and labeling accuracy are often the most pressing concerns, as inaccurate data can lead to poor model performance. Data labeling, especially for complex datasets, can be time-consuming and costly, requiring skilled personnel to ensure data is tagged accurately and consistently. Further, privacy issues arise when working with sensitive data, particularly in healthcare and finance, where personal information must be anonymized to comply with data protection regulations.
Another challenge lies in managing the sheer volume of data required for training sophisticated AI models. High-performance models often need vast amounts of data to achieve the desired accuracy, demanding substantial storage and processing capabilities. Ensuring that the data remains relevant and up-to-date is also essential, as outdated or irrelevant data can degrade the model’s effectiveness.
Future Trends in AI Training Datasets
The AI training dataset landscape is evolving as organizations seek ways to streamline data acquisition, reduce bias, and improve data diversity. Synthetic data generation is expected to play a more prominent role, allowing companies to create scalable and diverse datasets that can be customized to specific requirements. Advances in automation and AI-based data labeling tools are also poised to reduce the costs and time associated with preparing training datasets, making high-quality data more accessible.
Furthermore, collaboration between companies, research institutions, and governments may lead to the development of more comprehensive public datasets, enabling broader access to high-quality data. With growing awareness around privacy, federated learning—a technique that trains models across decentralized devices or servers while keeping data secure—might also become more popular, allowing AI systems to learn without compromising user privacy.
Conclusion
The AI training dataset is the backbone of modern machine learning and AI advancements, providing the essential data that powers intelligent systems across industries. As the AI Training Dataset Market continues to expand, driven by innovations and the rising demand for intelligent applications, the importance of high-quality, diverse, and ethically sourced datasets will only grow. With continuous developments in data generation, labeling, and privacy preservation, the future of AI training datasets promises to unlock even greater potential for AI systems, enabling them to perform more accurately, inclusively, and securely.
Contact Us:
Akash Anand – Head of Business Development & Strategy
info@snsinsider.com
Phone: +1-415-230-0044 (US) | +91-7798602273 (IND)
About Us
S&S Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Read Our Other Reports:
Team Collaboration Software Market Trends